Concurrence among Imbalanced Labels and its Influence on Multilabel Resampling Algorithms
This website contains additional material to the paper: F. Charte, A.J. Rivera, M.J. del Jesus, and F. Herrera "Concurrence among Imbalanced Labels and its Influence on Multilabel Resampling Algorithms". Proceedings of the 9th International Conference on Hybrid Artificial Intelligent Systems (HAIS 2014), June, Volume 8480, Salamanca (Spain), p.110-121, (2014) .
Abstract
In the context of multilabel classification, the learning from imbalanced data is getting considerable attention recently. Several algorithms to face this problem have been proposed in the late five years, as well as various measures to assess the imbalance level. Some of the proposed methods are based on resampling techniques, a very well-known approach whose utility in traditional classification has been proven.
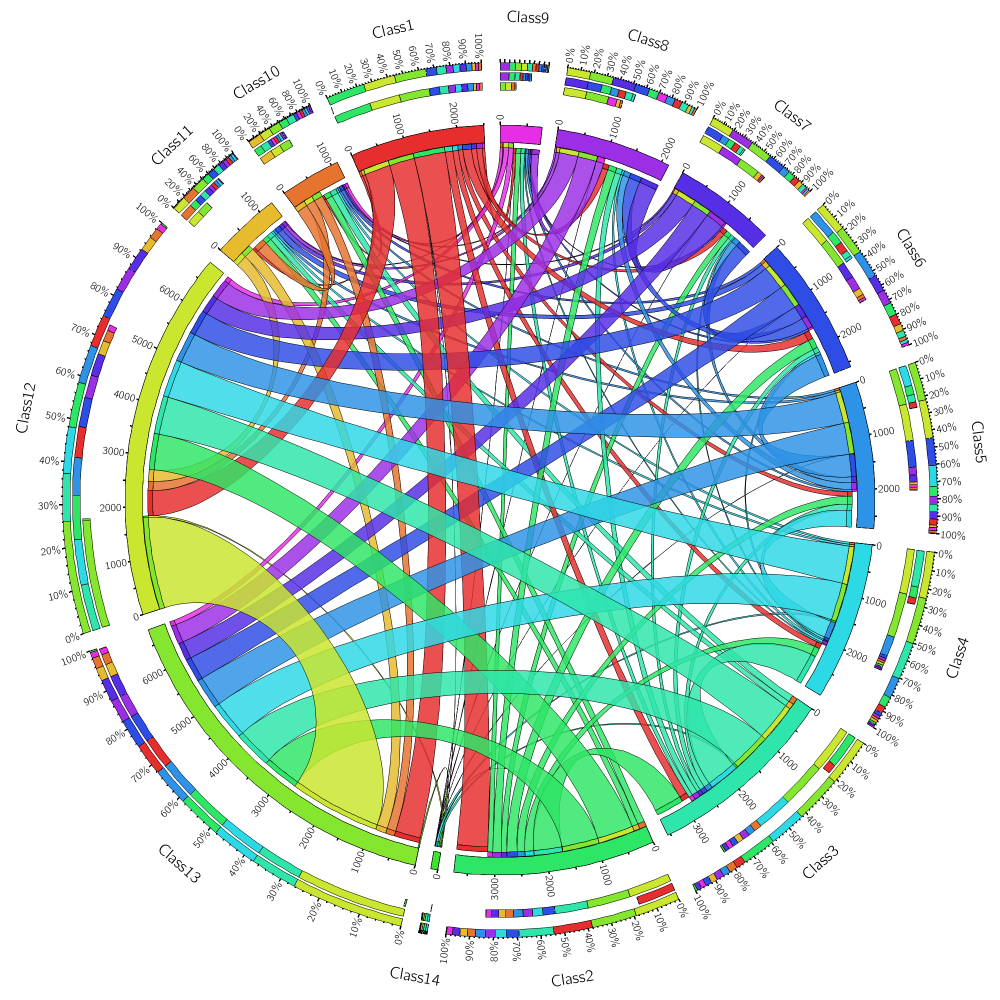
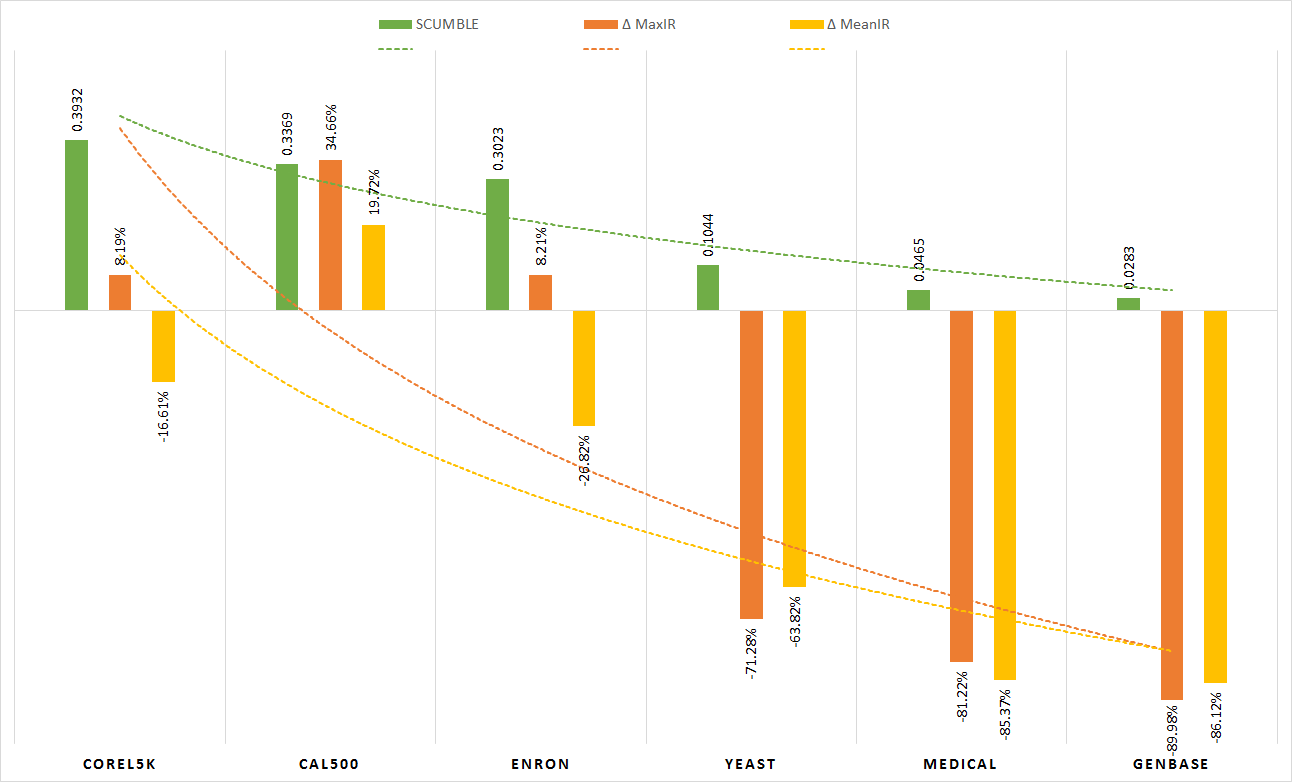
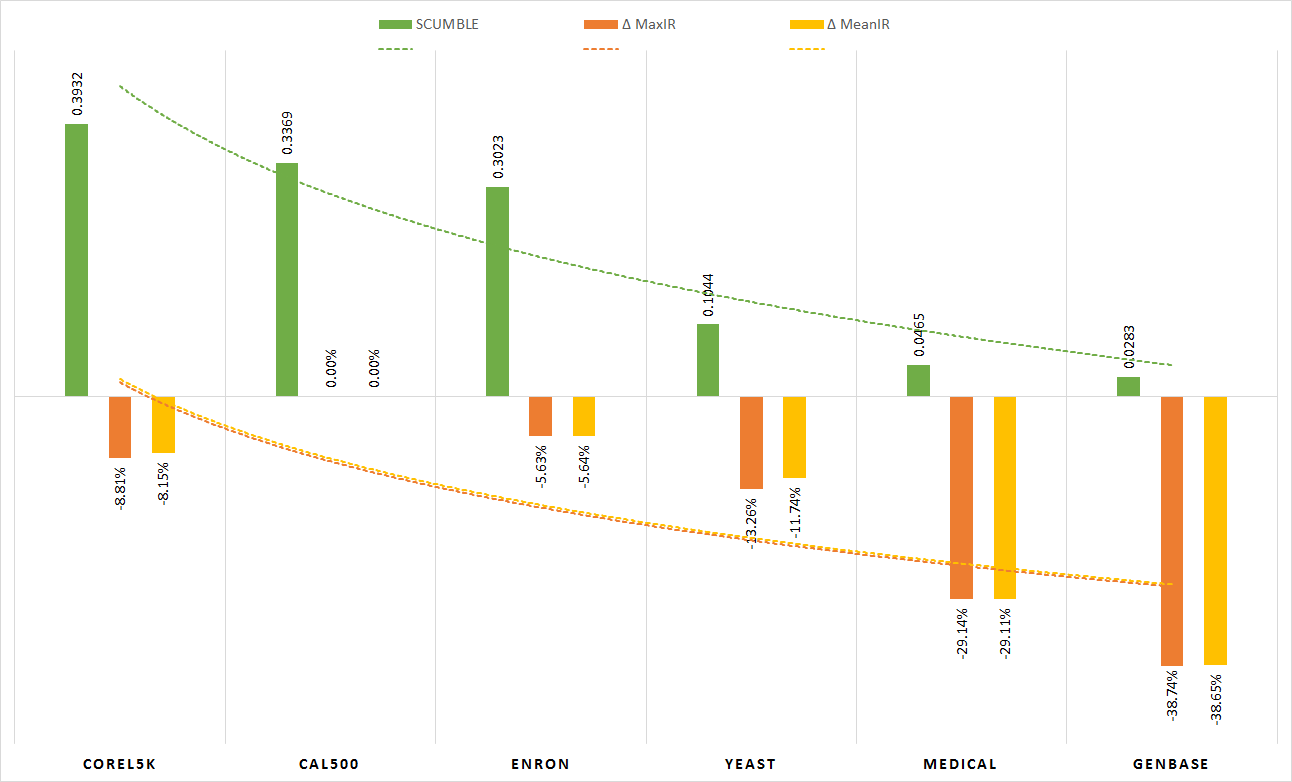
This paper aims to describe how a specific characteristic of multilabel datasets (MLDs), the level of concurrence among imbalanced labels, could have a great impact in resampling algorithms behavior. Towards this goal, a measure named SCUMBLE, designed to evaluate this concurrence level, is proposed and its usefulness is experimentally tested. As a result, a straightforward guideline on the effectiveness of multilabel resampling algorithms depending on MLDs characteristics can be inferred.
Datasets
The experimentation was conducted using the following 6 multilabel datasets. Each one of these datasets has been partitioned randomly twice in five separate partitions aiming to do a 2x5 folds cross validation, which means 10 runs of every algorithm for each dataset. These partitions are available to download.
| Dataset | # instances | # features | # labels | Card |
|---|---|---|---|---|
| cal500 | 502 | 68 | 174 | 26.044 |
| corel5k | 5000 | 499 | 374 | 3.522 |
| enron | 1702 | 1001 | 53 | 3.378 |
| genbase | 662 | 1186 | 27 | 1.252 |
| medical | 978 | 1449 | 45 | 1.245 |
| yeast | 2417 | 198 | 14 | 4.237 |
Color version of figures

Page created and maintained by Francisco Charte - 2014